Legacy System Migration

Leaving Legacy Data Management Behind Doesn't Have to Be Painful
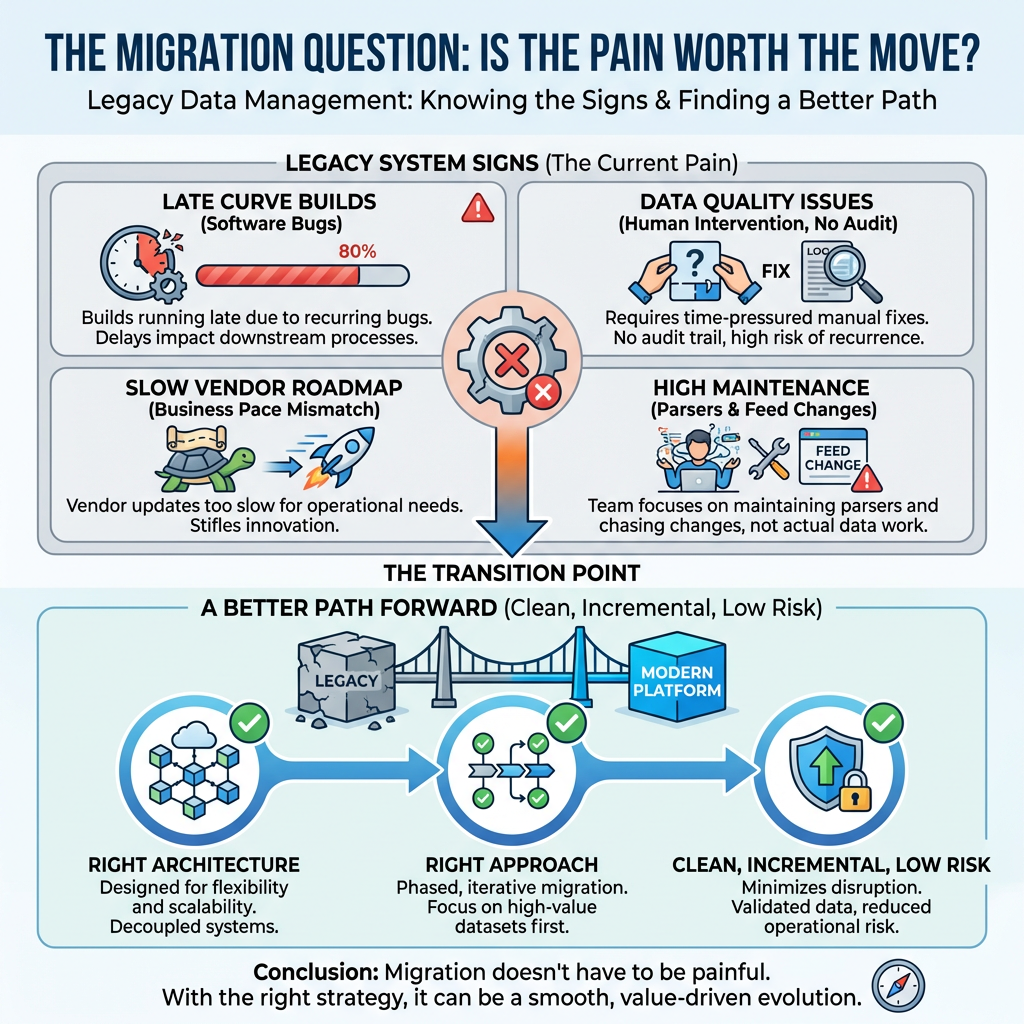
If your organisation is running a legacy data management system, you already know the signs. Slow curve builds. Software bugs that have been there for months. Data quality issues that require manual fixes under time pressure.
The question isn't whether to move - it's whether moving is worth the pain.
We think it doesn't have to be painful.
If your organisation is running a legacy data management system, you already know the signs.
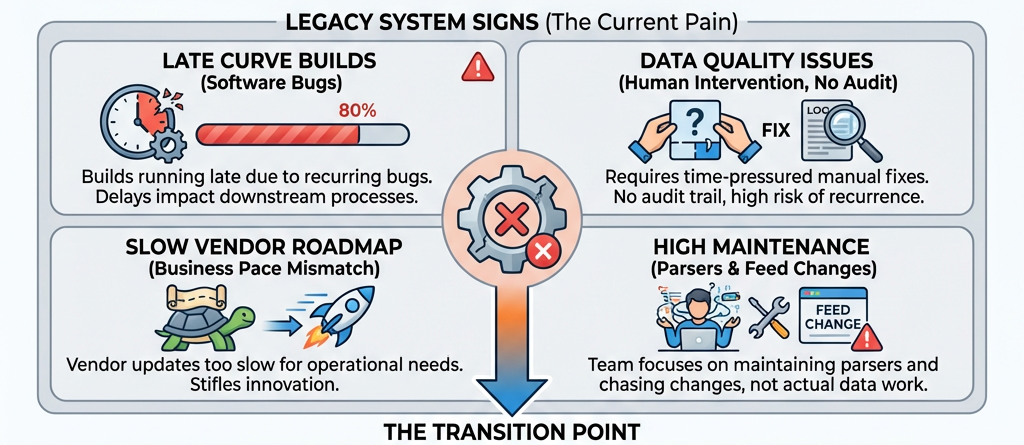
Curve builds running late because of a software bug. Data quality issues that require a human to intervene under time pressure - with no audit trail, and no guarantee it won't happen again tomorrow. A vendor roadmap that moves too slowly for the pace your business operates at. A team that spends more time maintaining parsers and chasing feed changes than doing actual data work.
The question isn't whether to move. The question is whether the move is worth the pain.
We've spent a lot of time thinking about this. And our conclusion is that migration away from a legacy data management platform does not have to be painful. With the right architecture and the right approach, it can be clean, incremental, and genuinely low risk.
The Problem With Legacy Platforms Isn't Just Features
When organisations talk about migrating away from legacy data management systems, the conversation often starts with features.
- What does the new platform have that the old one doesn't?
- Can it handle more data sources?
- Does it have better curve building?
- Is the API faster?
These are all reasonable questions. But they miss the deeper issue.
Legacy platforms were built in a different era, around a different set of assumptions. Processing was sequential. Compute was a scarce resource to be shared. Workflows were rigid. The idea that you might want to call a Python service from inside a curve build, or have AI assistants query your data in natural language, or spin up a new environment in seconds - none of that was on the design agenda.
The result is an architecture that creates systemic risk. When all your processing runs through a single shared resource, peak periods create backlogs. When the platform's extensibility is limited to what the vendor has built, your business is always waiting for someone else's roadmap.
These aren't bugs. They're design decisions that made sense in their time and don't make sense anymore.
The Migration Fear Is Real - And It's Usually About Risk, Not Cost
We talk to a lot of organisations about migration. And almost without exception, the biggest hesitation isn't the cost of the new platform. It's the risk of the transition.
When a data management system is deeply embedded in an organisation - feeding ten different downstream systems, used by hundreds of people in spreadsheets and applications, producing the curves that traders and risk managers rely on every day - the prospect of changing it feels enormous. What if something breaks? What if a system doesn't get its data? What if the migration takes longer than expected and both platforms are running in parallel indefinitely?
These are legitimate concerns. And they deserve a legitimate answer, not a dismissal.
Our answer is: don't migrate all at once. Never do it that way.
The Case for Phased Migration
The most effective migrations we've seen - and the ones we recommend to every prospective client - are phased. Not phased in the sense of "we'll do it slowly and hope for the best", but phased in the sense of a structured, deliberate plan where each phase delivers real value, each transition is independently reversible, and the legacy platform runs in parallel until every team is confident and ready to switch.
Here's what that looks like in practice.
Phase 1 proves the model, not the scale. Start with a subset of your full data universe - no new builds, no unknowns. Get the platform running in your environment. Connect one system. Show that the data flows correctly, that the curve business logic works, that the quality checks and approvals behave as expected. This phase is about confidence, not coverage.
Establish your standards early, before you scale. Before you start building out your full feed catalogue, invest time in defining your curve business flow.
- How does versioning work?
- What are your cut-off time rules?
- What happens when a broker publishes late?
- What does a quality check look like?
Get these right in a low-stakes environment and document them. Every feed you build from that point inherits the same standards automatically.
Build feeds at a sustainable rate. There's no value in rushing the feed build-out if it introduces errors. A consistent, predictable rate - say, twelve feeds per month - means your data team is never overwhelmed, quality is maintained, and stakeholders always know where you are in the process.
Decouple your system migrations from each other. This is the architectural insight that makes phased migration genuinely low risk. If the new platform pushes data to a central service bus, and each downstream system subscribes to the data it needs from that bus, then each system can migrate away from the legacy platform on its own timeline. One system's readiness doesn't block another's. There is no forced cutover. The legacy platform simply stops being needed, system by system, until it's safe to decommission.
Only pay for what's live. During the migration, your cost commitment should reflect your actual usage - not a projection of what you'll eventually need. Monthly billing for what's in production removes the financial risk from the transition and aligns the vendor's incentives with yours.
What Happens to Your Historical Data?
One of the most common concerns we hear is about historical data.
"We've been running this system for years. We have a decade of curves in there. We can't just leave that behind."
You don't have to.
Modern data platforms are built on document-oriented storage rather than relational tables. This actually makes migration easier than it sounds, because a relational table row and a document-store base event are structurally very similar - both are essentially named collections of key-value fields. There's no complex transformation logic required to move from one to the other.
In practice, this means that migrating historical data is largely a configuration exercise rather than a development project. You define the mapping, the platform handles the load, and your historical data arrives in its new home ready to use - versioned, queryable, and auditable - alongside everything that's been built natively on the new platform.
The Platform vs Product Distinction
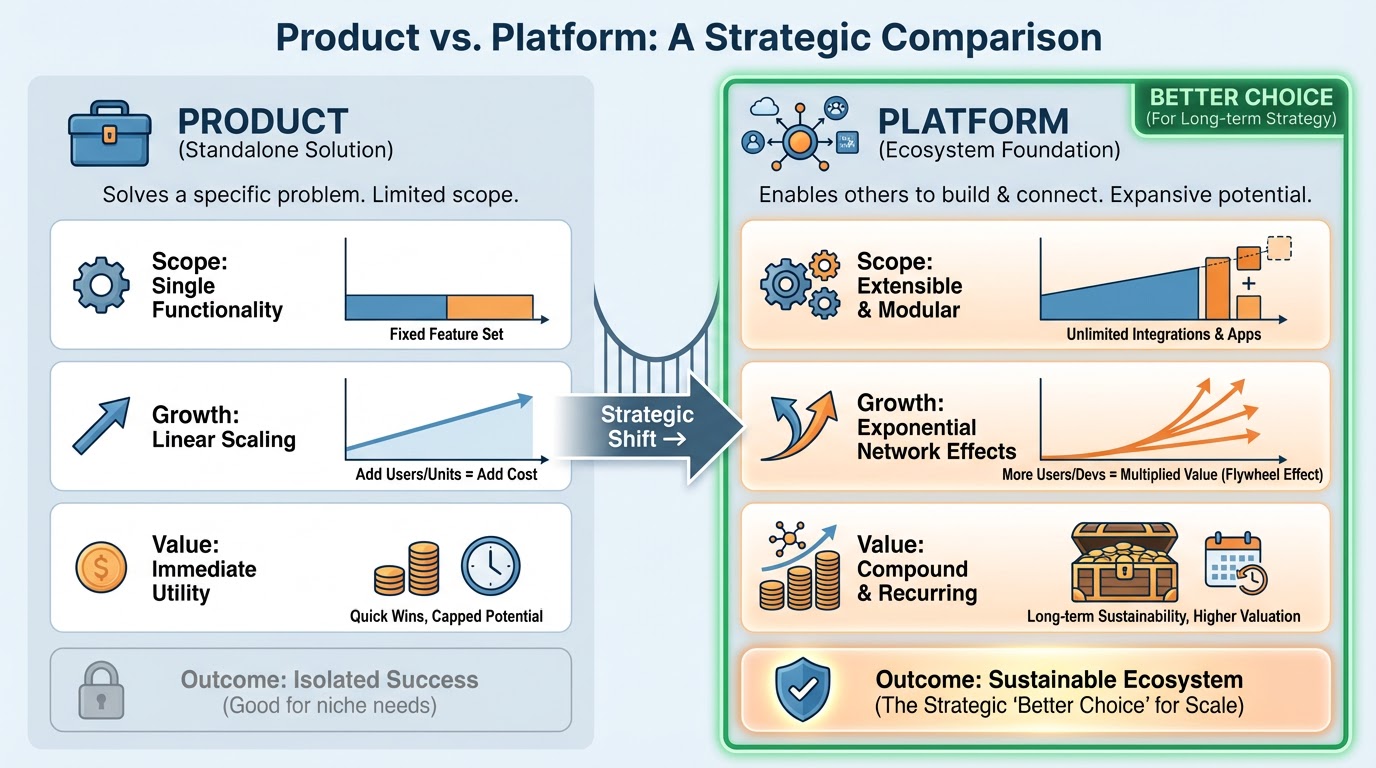
There's a question worth asking about any system you're considering as a migration target: is it a product or a platform?
A product is something a vendor builds and you consume. Features arrive on the vendor's timeline. If you need something that isn't on the roadmap, you wait. If a regulation changes, you raise a ticket. If you want to integrate with a new system, you negotiate. The vendor decides what gets built and when.
A platform is different. A platform gives you the tools to build what you need, when you need it.
- New data source? Build it yourself, or ask the platform team to build it for you - either way, it's live today, not in six months.
- New workflow? Write it in the platform's scripting language or call your existing Python service.
- New AI assistant trained on your own terminology and connected to your internal systems? Configure it and deploy it.
The distinction matters enormously when you're thinking about a migration. You're not just choosing a replacement for what you have. You're choosing the architectural foundation for the next decade of your data infrastructure. A platform gives you room to grow in ways you can't fully predict today. A product gives you a ceiling.
The AI Question
It would be disingenuous to write about modern data management without mentioning AI. Every platform claims to have it. Most implementations amount to a chatbot bolted onto a data catalogue.
The meaningful version of AI in a data management platform is one where the AI assistants are genuinely context-aware - where they understand not just the structure of your data but the content of it. Where an analyst can ask
"what data do we have for German power prices?"
and get a real answer, grounded in your actual environment, not a generic response. Where a developer can describe what they want to build in plain language and have the platform generate the code. Where an operations assistant can identify anomalies in your data pipeline before they become incidents.
This kind of AI integration isn't a feature you add later. It's something that has to be designed into the platform from the ground up, with the right architecture to support it. When you're evaluating migration targets, it's worth asking not just "does it have AI?" but
"How deeply is the AI integrated into how the platform actually works?"
A Note on What We've Learned
We've been through this migration journey with clients across the energy and commodities sector. A few things stand out.
The technical migration is almost never the hard part. The hard part is the organisational change - getting different teams to agree on a phasing plan, managing the parallel running period, deciding when it's safe to decommission the legacy system. The more you can do to make each phase independently valuable and each transition independently reversible, the easier those conversations become.
The data quality work that emerges during migration is almost always valuable in itself. The process of validating new feeds against existing data, defining quality rules, and documenting the curve business flow tends to surface problems that had been quietly tolerated for years. Migration is an opportunity to fix them, not just to replicate them.
And finally: the first phase is the most important. Not because it delivers the most - it won't, by design - but because it proves to everyone in the organisation that the migration is real, that it works, and that the new platform does what it's supposed to do. Get phase one right and the rest of the programme has momentum. Stumble in phase one and you'll be fighting scepticism for the rest of the journey.
Where to Start
If you're running a legacy data management platform and you're thinking about what comes next, the best starting point is usually a structured conversation about what's actually causing you pain. Not a sales call - a diagnosis.
- What are the failure modes that keep happening?
- Where is your team spending time that should be spent on something else?
- What can't your current platform do that your business needs it to do?
From those answers, it's usually possible to sketch out a phase one that's meaningful, low risk, and achievable within a month. Something real enough to prove the concept, constrained enough to be safe, and useful enough that the people running it can see immediately why the new platform is better.
Migration doesn't have to be a big bang. It doesn't have to be a project that runs for two years and costs a fortune before anyone sees any value. Done well, it can be incremental, transparent, and surprisingly straightforward.
The legacy platform doesn't get switched off on day one. It gets switched off on day three hundred and thirty, after ten teams have independently validated their data, migrated their connections, and decided they don't need it anymore.
That's not painful. That's just good engineering.
Interested in discussing what a migration from your current platform could look like? Get in touch with the OpenDataDSL team - we're happy to start with a conversation, not a pitch.
Get in touch with the OpenDataDSL team today
OpenDataDSL is a modern, cloud-native data management platform built for energy and commodities markets. From market data ingestion to ETRM integration, OpenDataDSL gives trading organisations the control, visibility, and flexibility they need to compete.
Fill out the form below, we will contact you to arrange a personally tailored demo.
How about a demo?
Our team is here to find the right solution for you, contact us to see this in action.
Fill out your details below and somebody will be in contact with you very shortly.