Running Python Tasks

Run Python Inside OpenDataDSL
OpenDataDSL has always been designed around flexibility. Our ODSL language gives energy and commodity trading professionals a powerful, domain-native way to build data pipelines, model curves, and manage complex data assets. But we've long recognised that the broader data and quant world runs on Python, and for many teams, R, NodeJS, or other specialised tools are equally central to their workflow.
That's why we've built something we're genuinely excited about: native support for running Python. directly as part of your OpenDataDSL processes. No wrappers, no hacks, no separate orchestration layer - just seamless integration with everything else on the platform.
Why This Matters
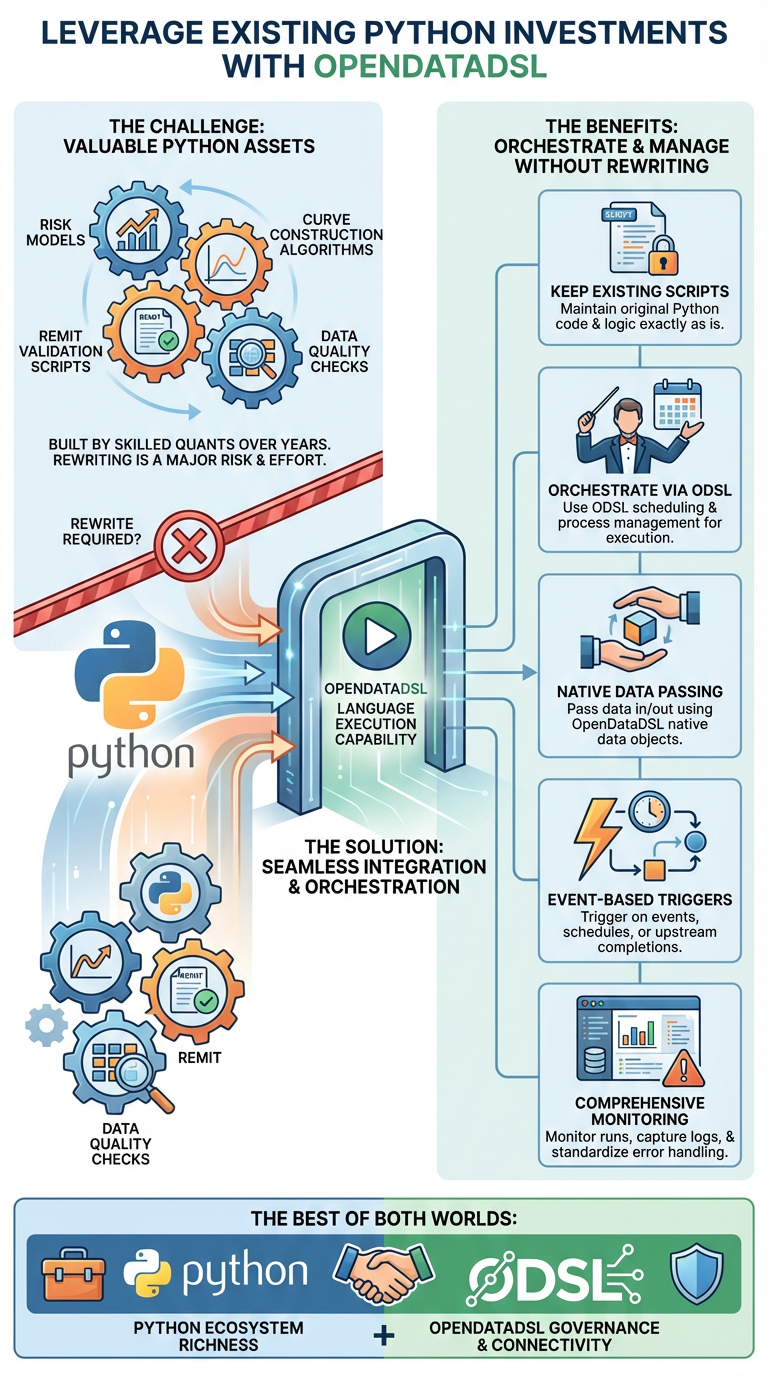
Energy and commodity trading firms have significant investments in Python-based tooling. Risk models, curve construction algorithms, REMIT validation scripts, and data quality checks are often built by skilled quant teams over years. The last thing anyone wants is to be forced to rewrite that logic in a new language just to deploy it through a data platform.
With OpenDataDSL's new language execution capability, you don't have to choose. You can:
- Keep your existing Python scripts exactly as they are
- Orchestrate them through ODSL's scheduling and process management
- Pass data in and out using OpenDataDSL's native data objects
- Trigger executions based on events, schedules, or upstream process completions
- Monitor runs, capture logs, and handle errors through the standard platform tooling
It's the best of both worlds - the familiarity and ecosystem richness of Python, combined with the governance, connectivity, and data management capabilities of OpenDataDSL.
Whether you're building an ETL pipeline, validating data against business rules, constructing smart curves, or running a quant model — you can now bring your existing Python scripts into the OpenDataDSL ecosystem and run them as first-class processes.
Key Use Cases
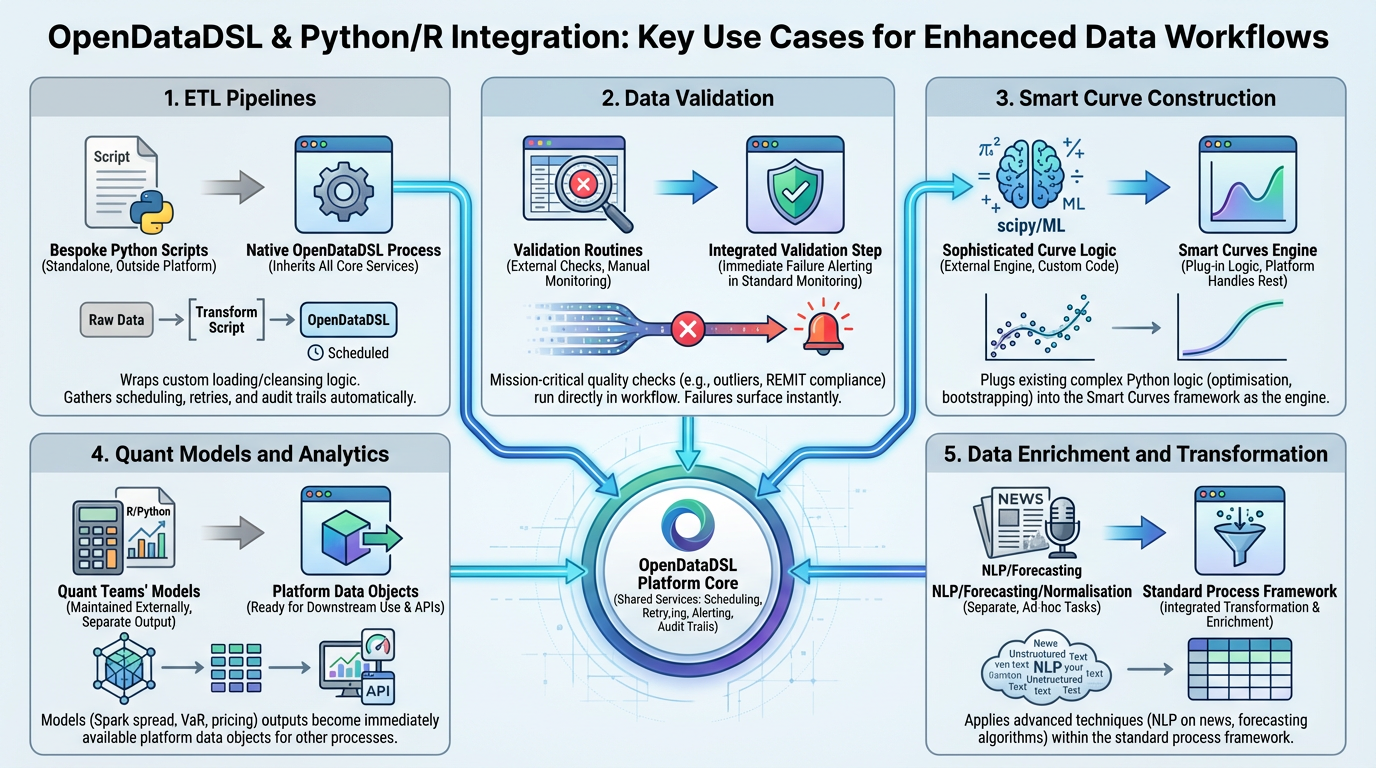
ETL Pipelines
Many data teams maintain bespoke Python-based ETL processes for loading data from proprietary APIs, transforming complex formats, or applying custom cleansing logic before persisting into OpenDataDSL. Previously, these would run as standalone scripts outside the platform. Now, you can wrap them as native OpenDataDSL processes — inheriting scheduling, retry logic, alerting, and audit trails.
Data Validation
Data quality is mission-critical in energy trading. Python-based validation routines — whether checking for outliers in price curves, verifying REMIT message compliance, or validating physical delivery positions against capacity constraints — can now run as validation steps directly within an OpenDataDSL workflow. Failed validations surface immediately in the platform's standard monitoring.
Smart Curve Construction
Smart Curves in OpenDataDSL allow you to build derived, enriched price curves from raw market data. For teams with sophisticated curve-building logic already expressed in Python — whether using scipy optimisation, custom bootstrapping, or machine learning models — this capability lets you plug that logic directly into the Smart Curves framework. Your Python code becomes the engine; OpenDataDSL handles everything else.
Quant Models and Analytics
Spark spread calculations, VaR models, options pricing, emissions cost overlays — these are often developed and maintained by quant teams in Python or R. Running them through OpenDataDSL means your model outputs are immediately available as platform data objects, ready for downstream use by other processes, dashboards, or APIs.
Data Enrichment and Transformation
Need to apply NLP to extract structured data from news feeds? Run a Python forecasting model over consumption data? Apply a proprietary normalisation algorithm to cross-venue price data? All of this is now possible within the standard OpenDataDSL process framework.
How It Works
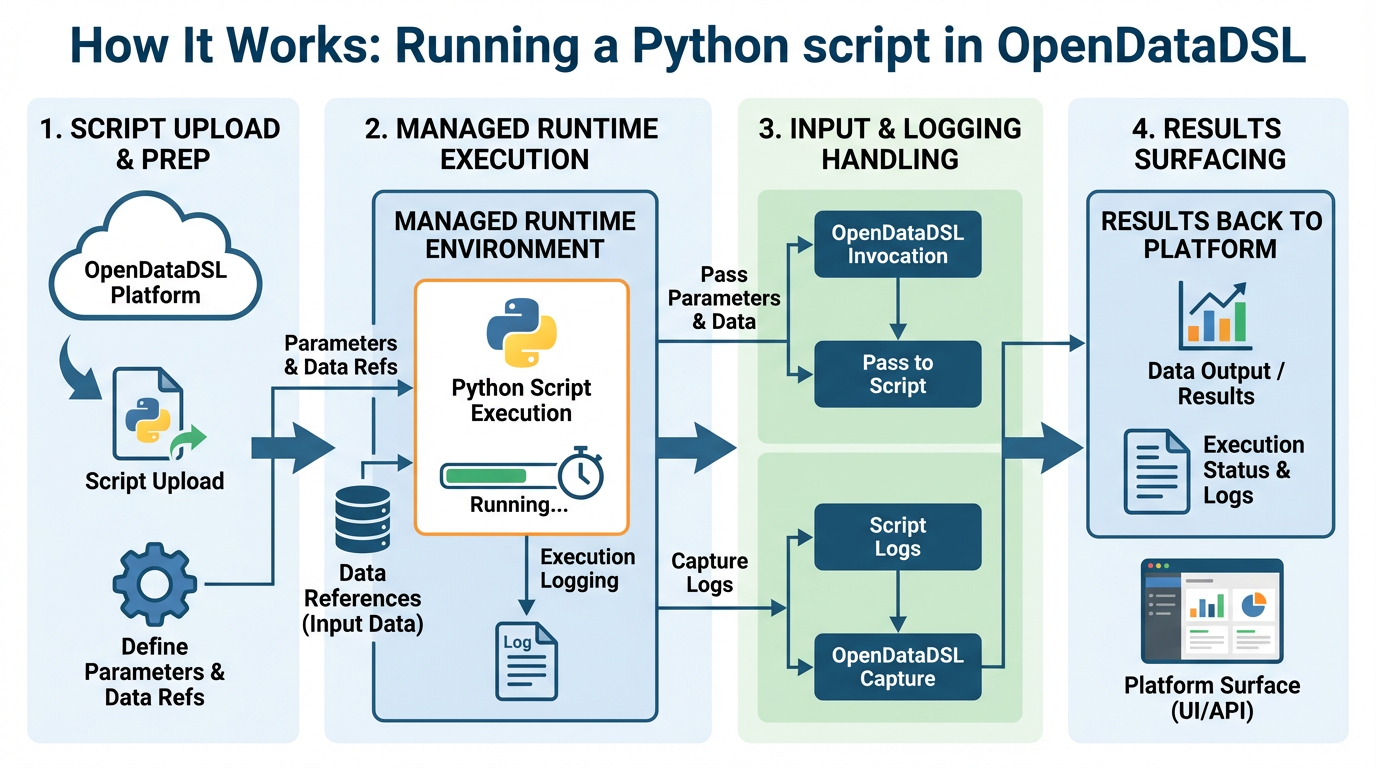
Running a Python script in OpenDataDSL is straightforward. Scripts are uploaded into the platform and executed within a managed runtime environment. OpenDataDSL handles the invocation, passes in any required parameters and data references, captures execution logging, and surfaces results back to the platform.
A simple example — running a Python curve building script as part of a data ingestion process:
async def main():
# Get the input data
input = t['input']
objid = input['objid']
name = input['name']
base = input['base']
ondate = input['ondate']
# Get the base curve
await PROCESS.logMessage("INFO", "Getting base curve " + base)
base_curve = SDK.get('data', 'private', base + ":" + ondate)
# Create the object to update
await PROCESS.logMessage("INFO", "Building " + objid + ":" + name)
obj = {'_id': objid}
# Call a python timespread function
obj[name] = timespread(base_curve).data
# Update the curve
SDK.update('object', 'private', obj, {'_origin':t['name']})
await PROCESS.endPhase("success", "Updating Successfully")
await PROCESS.endProcess("success", "Completed Successfully")
The Python script itself can be any standard Python — it can import libraries, access the OpenDataDSL Platform, call external APIs, or do heavy numerical computation. The OpenDataDSL runtime manages the environment, so scripts run in a consistent, controlled context.
Supported runtimes include Python 3.x, Node JS, and other languages and executables — giving teams the freedom to use whatever tool is best suited to the task.
Integration with the Broader Platform
What makes this particularly powerful is how deeply it integrates with everything else in OpenDataDSL. Your Python process is not running in isolation — it's a node in a larger graph of platform capabilities:
- Scheduling and orchestration: trigger Python scripts on a cron schedule, on data arrival, or as downstream steps in a multi-stage pipeline
- Data access: read and write OpenDataDSL data objects directly, including TimeSeries, Curves, and DataSets
- Monitoring and alerting: all executions are logged; failures trigger standard platform alerts
- Fusion AI integration: Python processes can be invoked by AI agents within Fusion, enabling AI-driven automation of complex analytical workflows
- Audit and governance: every run is traceable, with inputs, outputs, and execution metadata captured for compliance and debugging
This means Python becomes a natural extension of the ODSL language rather than an escape hatch. Teams can mix and match ODSL and Python within the same process, using each where it's most appropriate.
Security: Running with the Right Permissions
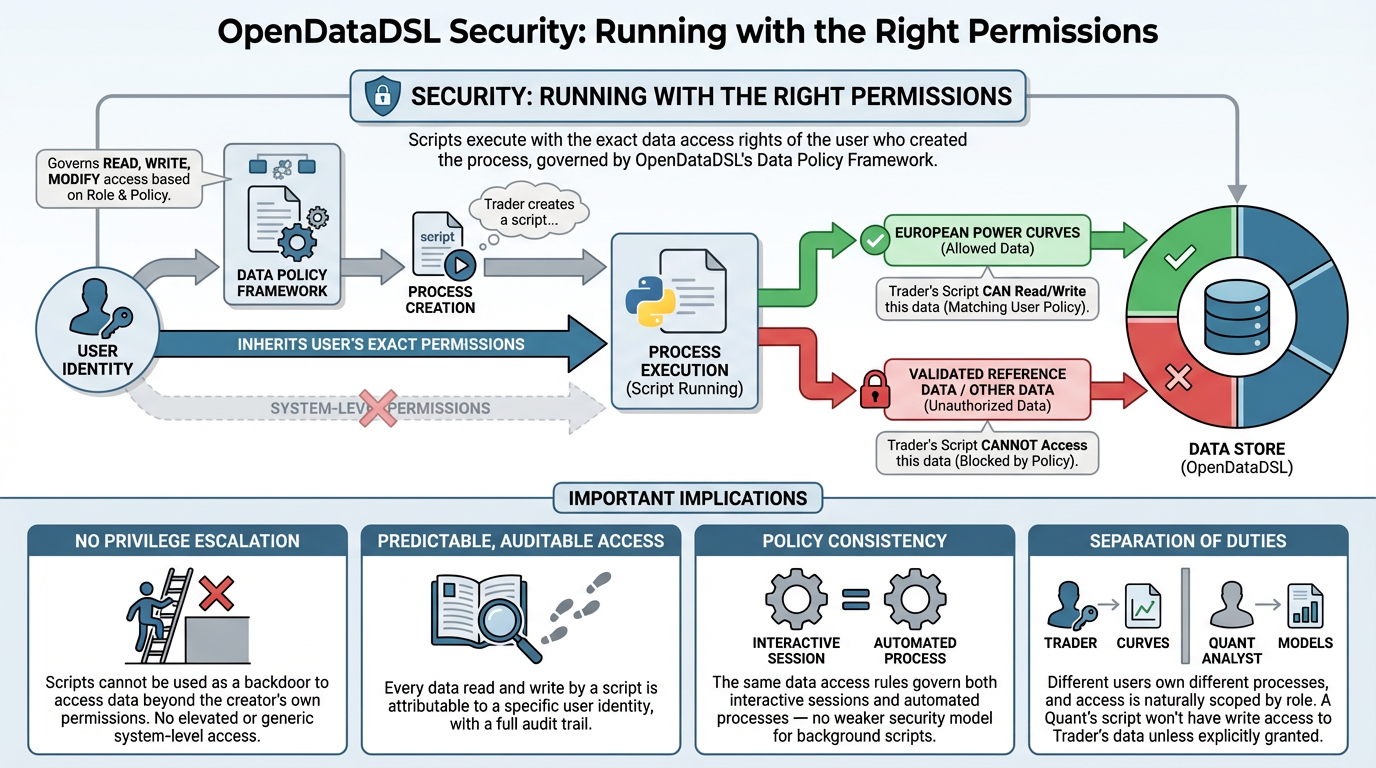
One of the most important aspects of any process execution framework is security — and this is an area we've thought about carefully.
When a Python (or any language) script runs in OpenDataDSL, it does not run with elevated or generic system-level permissions. Instead, it runs with exactly the data access rights of the user who created the process. OpenDataDSL's data policy framework governs what data each user can read, write, and modify — and those same policies apply when their processes execute scripts. A process created by a trader with access to European power curves can only read and write European power curves. It cannot access data that the creating user couldn't access themselves.
This has several important implications:
- No privilege escalation: scripts cannot be used as a backdoor to access data beyond the creator's own permissions
- Predictable, auditable access: every data read and write made by a script is attributable to a specific user identity, with a full audit trail
- Policy consistency: the same data access rules that govern interactive user sessions apply equally to automated processes — there's no separate, weaker security model for background scripts
- Separation of duties: different users can own different processes, and access is naturally scoped by role — a quant analyst's curve-building script won't have write access to validated reference data unless they've been explicitly granted it
This means that bringing Python into your OpenDataDSL workflows doesn't introduce a security blind spot. Your data governance policies remain intact and consistently enforced, regardless of how a process is triggered or what language it runs in.
For enterprise teams with strict data access controls — common in energy trading environments where different desks have segregated views of position and pricing data — this is a critical guarantee. Scripts run with least-privilege by design, not by configuration.
What This Means for Your Team
For data engineers and quant developers, this removes a significant friction point. Instead of maintaining a separate orchestration layer (Airflow, cron jobs, Azure Functions) just to run Python scripts alongside your OpenDataDSL processes, everything can now live and run in one place.
For platform administrators and compliance teams, it means that even Python-based processes benefit from OpenDataDSL's governance model — standardised logging, access controls, and audit trails, rather than scripts running on ad-hoc servers with no visibility.
For commercial teams evaluating the platform, it means that your existing Python investment is an asset, not a barrier. Migration to OpenDataDSL doesn't require rewriting everything — it means augmenting what you have.
Getting Started
If you're already an OpenDataDSL customer, reach out to your account team to enable Python execution for your environment. We're working with a number of early adopters to refine the runtime configuration options and extend library support.
If you're evaluating OpenDataDSL and want to understand how your existing Python tooling could fit into the platform architecture, we'd love to walk through a technical proof-of-concept with you.
Ready to bring your Python workflows into OpenDataDSL? Contact us at info@opendatadsl.com or book a technical deep-dive through our website.
Fill out the form below, we will contact you to arrange a personally tailored demo.
How about a demo?
Our team is here to find the right solution for you, contact us to see this in action.
Fill out your details below and somebody will be in contact with you very shortly.